3661. Installing Spark on UbuntuApache Spark and Scala
Install Spark, Scala on Ubuntu
1. What is Apache Spark?
Apache Spark is a lightning-fast cluster computing designed for fast computation. It was built on top of Hadoop MapReduce and it extends the MapReduce model to efficiently use more types of computations which includes Interactive Queries and Stream Processing.
2. Installing Java and Scala
2.1 Installing JDK
Refer to Setting up Java Development Environment on Ubuntu to install JDK on Linux. Check java version with the following command.
$ java -version
java version "1.8.0_144"
Java(TM) SE Runtime Environment (build 1.8.0_144-b01)
Java HotSpot(TM) 64-Bit Server VM (build 25.144-b01, mixed mode)
2.2 Installing Scala
Go to http://www.scala-lang.org/download/, download scala-2.12.3.deb. Navigate to the folder where the new installation file locates. Install Scala with following command.
$ sudo dpkg -i scala-2.12.3.deb
Verify Scala installation by checking Scala version.
$ scala -version
Scala code runner version 2.12.3 -- Copyright 2002-2017, LAMP/EPFL and Lightbend, Inc.
3. Installing Spark
3.1 Downloading Spark
Go to https://spark.apache.org/downloads.html, select release and package type, download spark-2.2.0-bin-hadoop2.7.tgz.
Extract the spark tar file with the following command.
$ tar xvf spark-2.2.0-bin-hadoop2.7.tgz
Move spark files to /usr/local/spark.
$ mv spark-2.2.0-bin-hadoop2.7 /usr/local/spark
3.2 Setting up the environment for Spark
Open ~/.bashrc file with any text editor.
$ nano ~/.bashrc
Add the following line to ~/.bashrc file.
export PATH=$PATH:/usr/local/spark/bin
Source the bash file
$ source ~/.bashrc
3.3 Verifying the Spark Installation
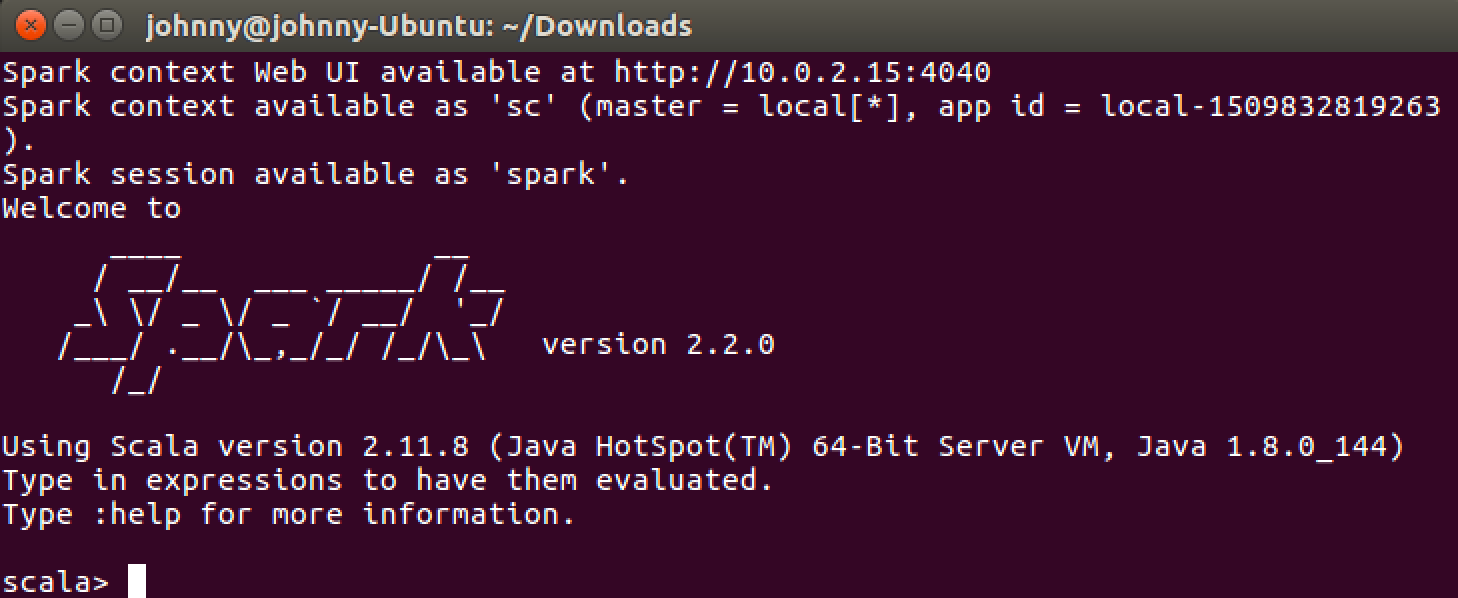
Launch Spark Shell with following command.
$ spark-shell
You will get the following output if spark is installed successfully.
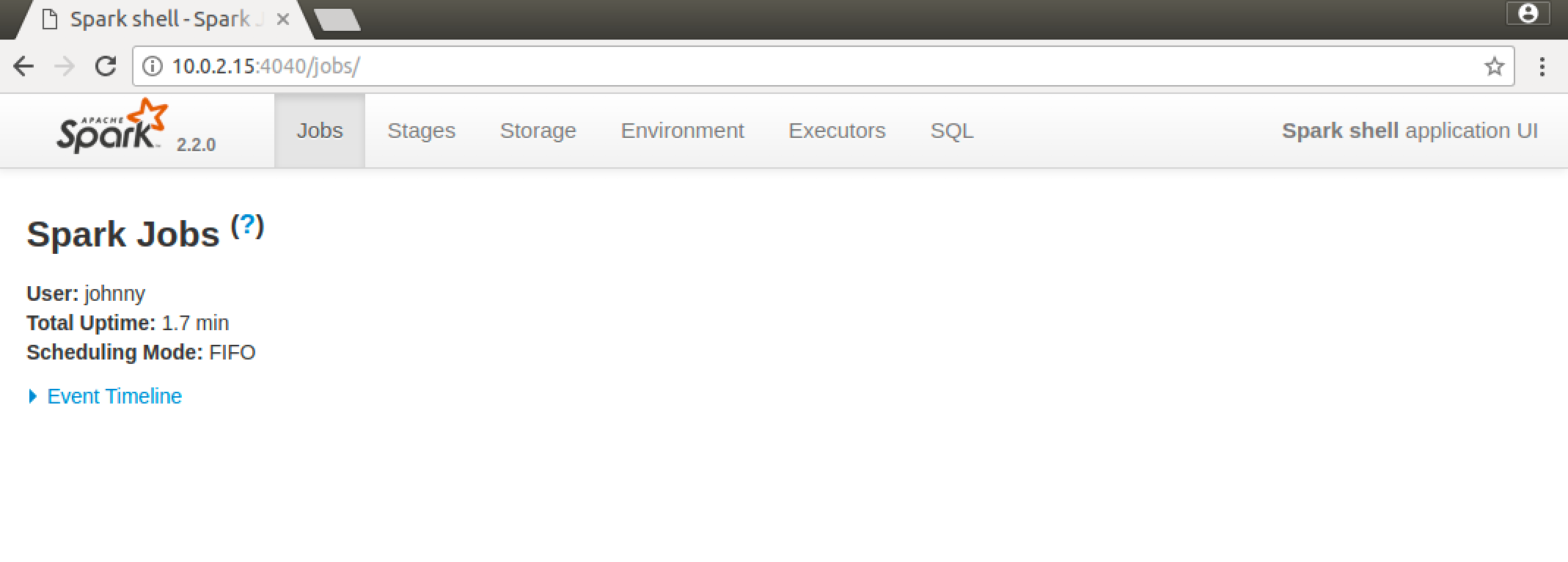
Access http://10.0.2.15:4040/jobs/ in web browser to open Spark Web UI.